
特征一
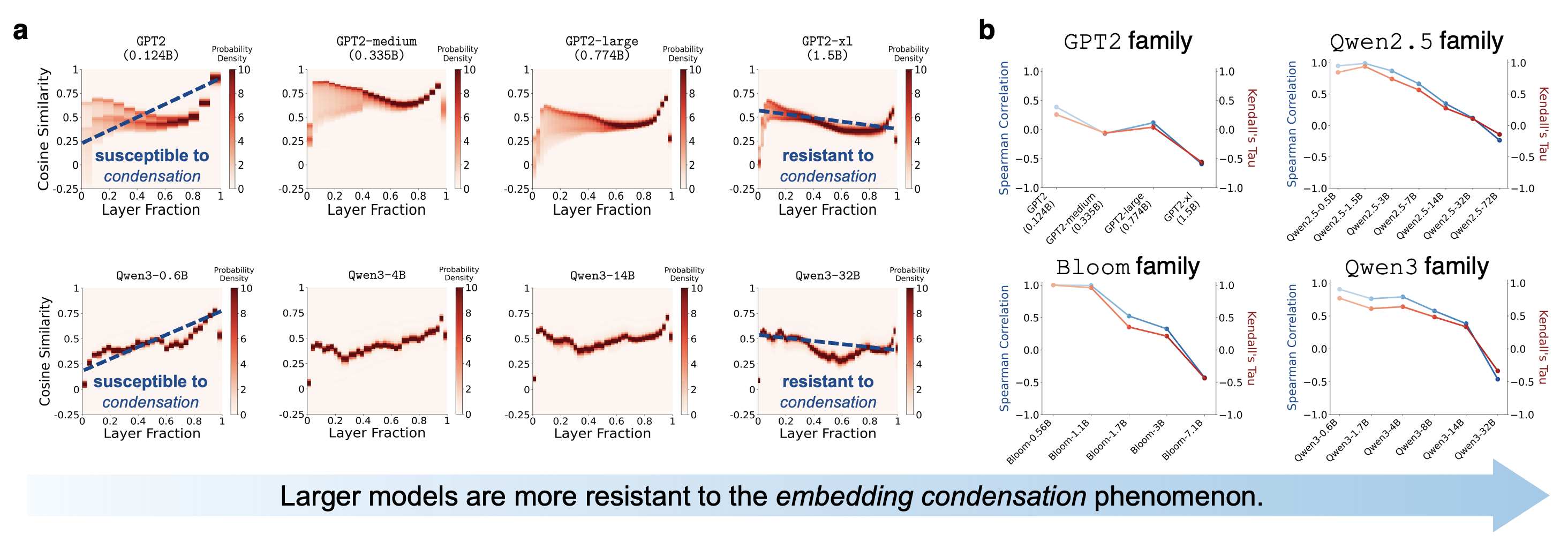
模型越大,塌缩越弱(见图二)。
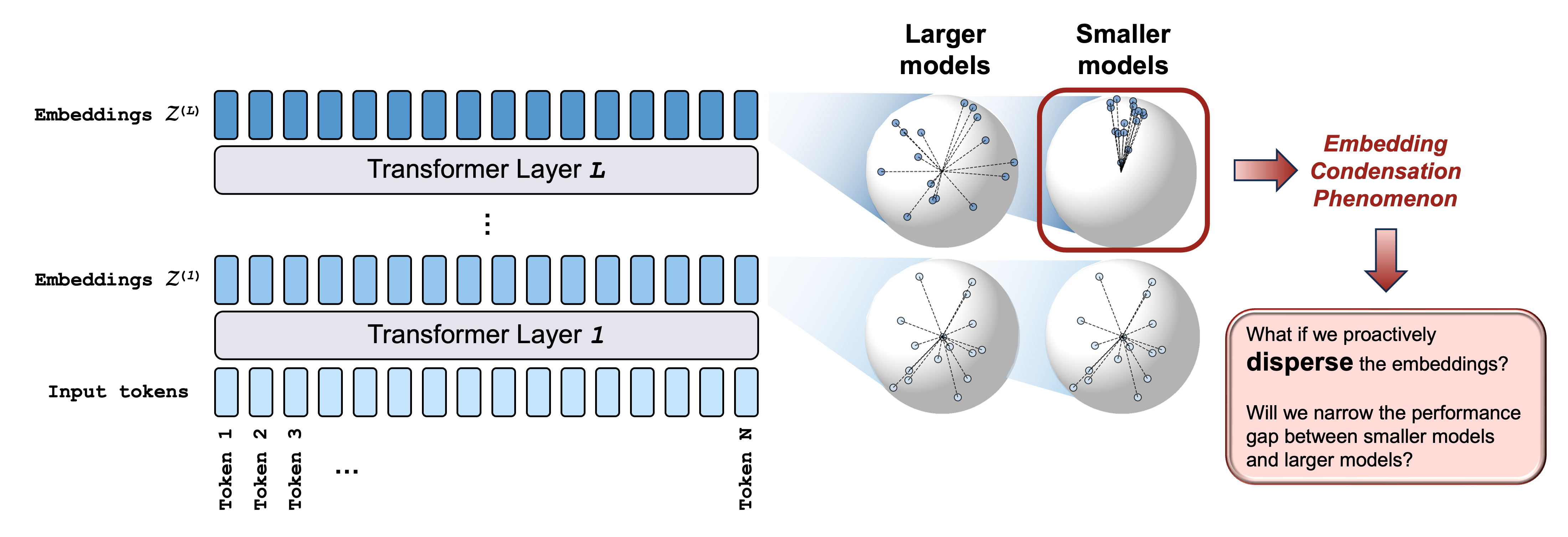
大语言模型为什么比小语言模型强?数据?参数?几何结构或许也颇为关键!
现在基于 Transformer 架构的大语言模型的每一层会把每个输入 token 表示为嵌入空间中的高维向量(通常每一层对应的空间维度均相等)。 随着向量逐层前传,我们发现这些向量常常像是被挤进一个狭窄圆锥里: token 表征两两之间指向的方向越来越趋同。我们把这种几何现象称为嵌入塌缩 (embedding condensation)。该现象具有以下特点:
模型越大,塌缩越弱(见图二)。
控制变量后依然存在(见图三)。
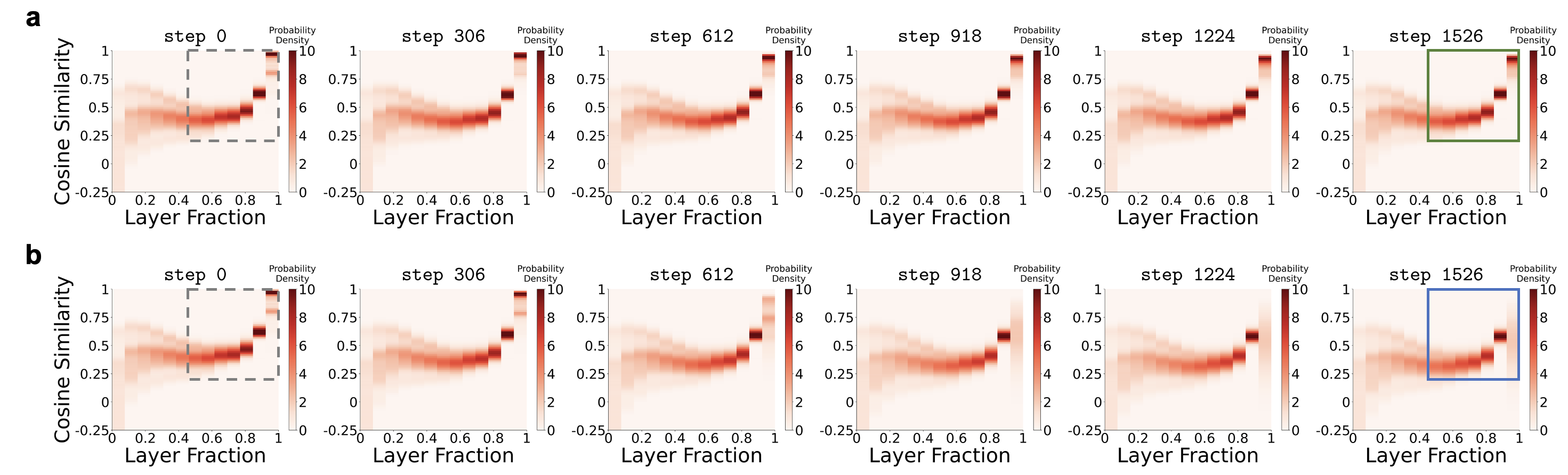
模型初始化时就已萌芽,并被预训练缓解(见图四)。
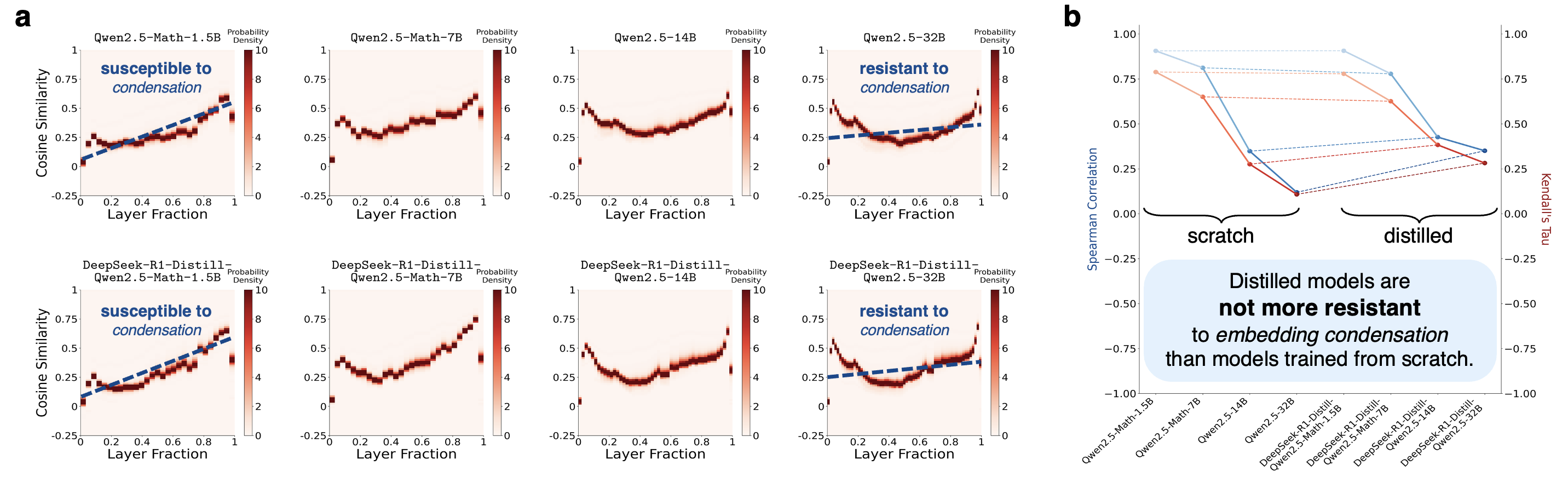
知识蒸馏无法解决(见图五)。
为什么小语言模型比大语言模型弱?一个直观答案当然是参数少、数据少、算力少。 但如果我们打开模型内部,看它每一层的 token 表征,会不会发现一些更具体的差异?
我们最近从表征空间的几何结构出发,观察到一个很有意思的现象。我们称之为嵌入塌缩: 在小语言模型中,token 的表征往往会坍缩到狭窄的锥形子空间内。为了对抗这一现象,我们设计了一个损失函数 dispersion loss 。
特征一:模型越大,塌缩越弱
这个现象在小模型中尤其明显。
在同一个模型家族里,模型越小,token 表征越容易在深层发生这种
“方向挤压”。越大的模型通常对这种现象越有抵抗力。
我们换了四个文本数据集,都能复现这个现象。
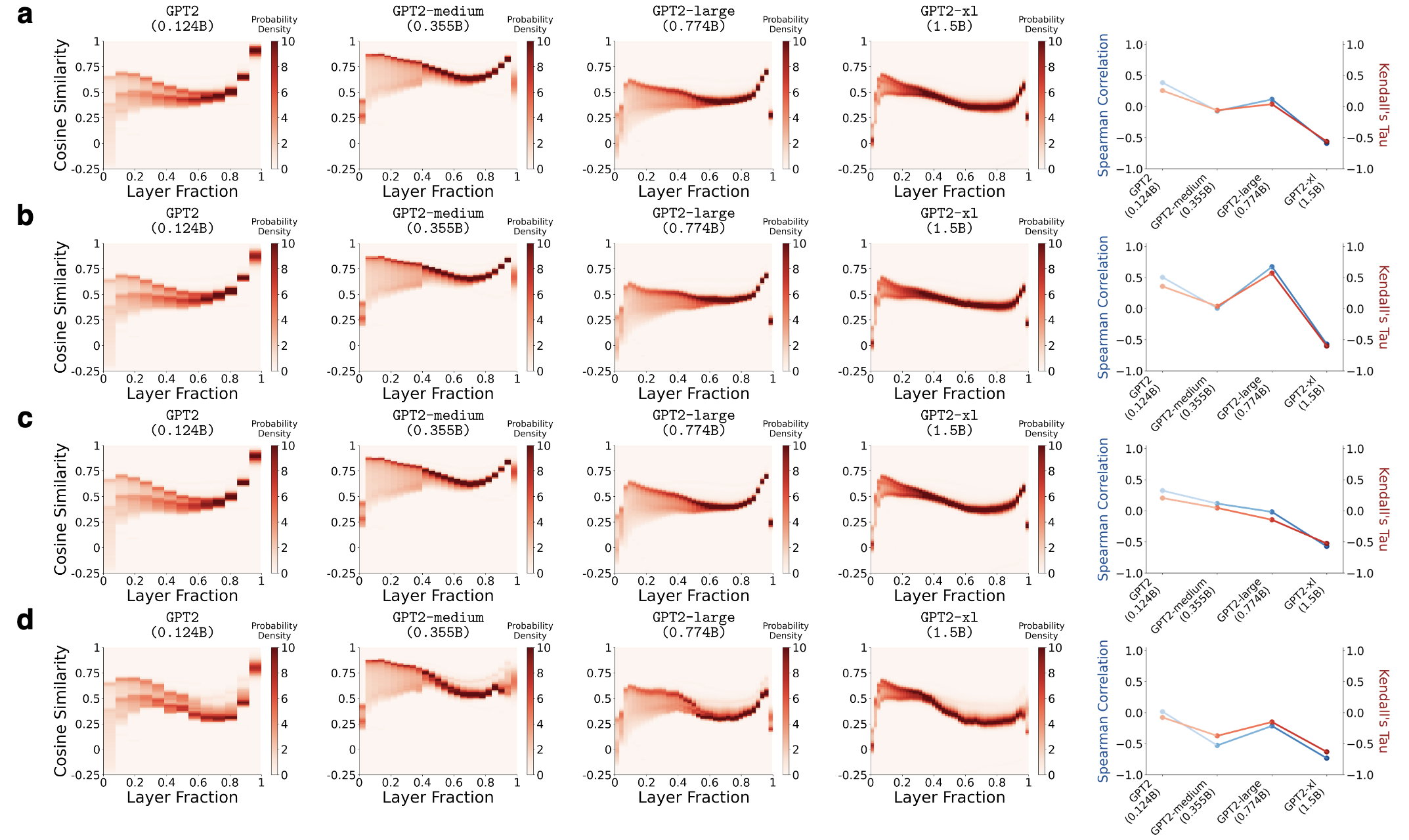
wikitext,(b)
pubmed_qa,(c) imdb,(d) squad
特征二:控制变量后依然存在
为了排除干扰因素,
我们还训练了一组基于 GPT2 的变种。
我们特意只改变 MLP 宽度,保持其他所有变量完全一致,
包括层数、嵌入维度、训练数据和训练设置。
结果发现,“模型越大,塌缩越弱”的趋势仍然存在。

这说明嵌入塌缩不只是某个具体模型或某个训练设置下的偶然现象,而可能反映了小语言模型在表征空间利用上的一种系统性限制。
特征三:模型初始化时就已萌芽
有一个略微反直觉的发现是,
这个现象在模型初始化时就已经存在。模型在真正开始学习之前,它的表征空间几何结构就已经表现出这种
“挤在一起”的倾向。预训练会在一定程度上缓解、而非加剧这一现象。
特征四:知识蒸馏无法解决
有人可能会问:
既然大模型不怎么塌缩,那我们直接蒸馏大模型不就解决了吗?
凭直觉而言,如果一个小模型向一个大模型学习,也许它的表征空间会变得更像大模型。
但实验显示,蒸馏虽然可以约束输出分布,却并不会自然修复中间层表征的几何结构。
换句话说,学生可以学到老师的答案,但不一定学到老师的内部空间组织方式。
基于这些观察,我们提出了一个简单的训练正则项,叫 dispersion loss。
它的想法很直接:如果 token 表征在角度上太挤,那我们就在训练时显式鼓励它们分散开。 这有点像把原本挤成一团的向量摊开,让模型使用更多的表征方向。
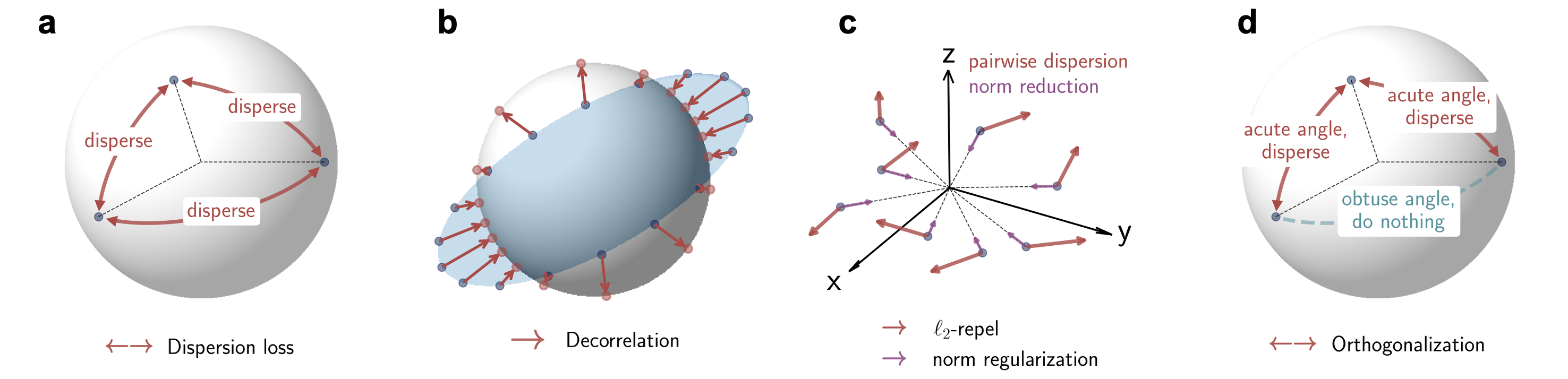
我们 dispersion loss 的设计很大程度上借鉴了 凯明大神和 Runqian 的一篇文章,但略作调整。对比如下。

我们通过实验发现,这个简单的几何约束可以有效缓解嵌入塌缩。
在 mid-training 和 pre-training 中,使用 dispersion loss 能够给小语言模型带来一定的泛化提升。详情可见最新版文章。
大模型的优势,可能不只是“更大”, 而是它更充分地利用了表示空间。而这也许可以通过训练目标来部分弥补。
若你打算复现本文或借鉴其中部分思路,以下是我们的一点个人建议。
我个人觉得以下几方面可能值得关注。
@inproceedings{liu2026dispersion,
title={Dispersion loss counteracts embedding condensation and improves generalization in small language models},
author={Liu, Chen and Sun, Xingzhi and Xiao, Xi and Van Tassel, Alexandre and Xu, Ke and Reimann, Kristof and Liao, Danqi and Gerstein, Mark and Wang, Tianyang and Wang, Xiao and Krishnaswamy, Smita},
booktitle={International Conference on Machine Learning},
year={2026},
organization={PMLR}
}