
Feature 1
More severe in smaller models than in larger counterparts (Figure 2).
What makes LLMs better than small LMs? Data? Parameters? Geometry might play a role!
Every Transformer layer of a language model represents each input token as a vector in a high-dimensional embedding space. We notice that as those vectors progress through Transformer layers, they often behave as if they were confined to a narrow cone: they point to increasingly similar directions as measured by pairwise cosine similarity. We call this geometric phenomenon embedding condensation. This phenomenon is:
More severe in smaller models than in larger counterparts (Figure 2).
Reproducible under confounder-controlled settings (Figure 3).
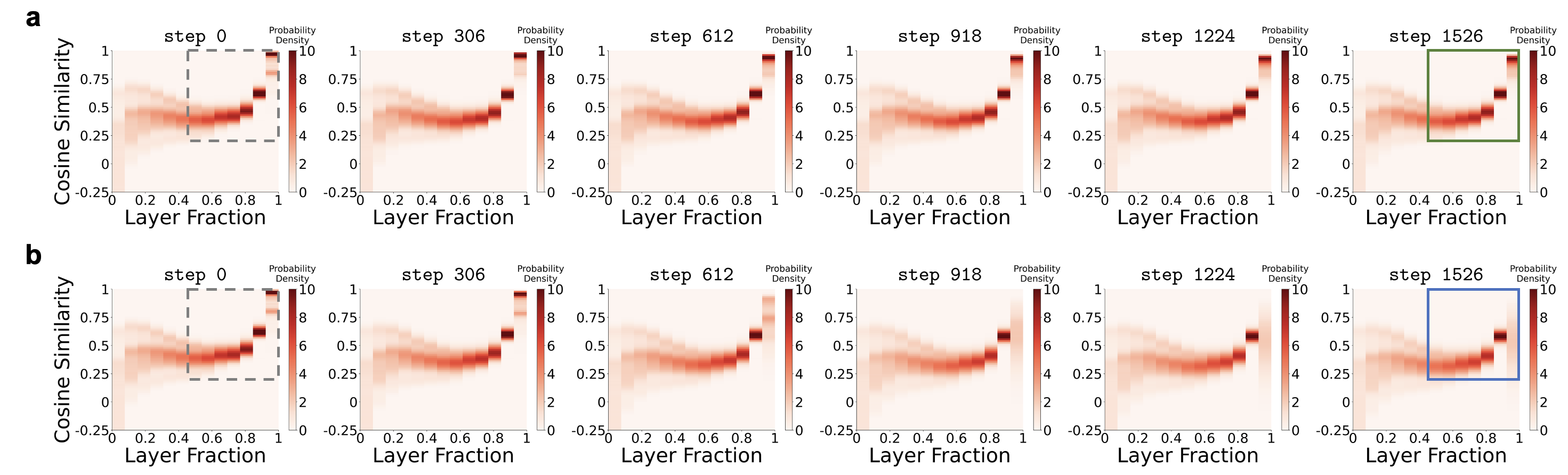
Emerging at model initialization and gets alleviated by pre-training (Figure 4).
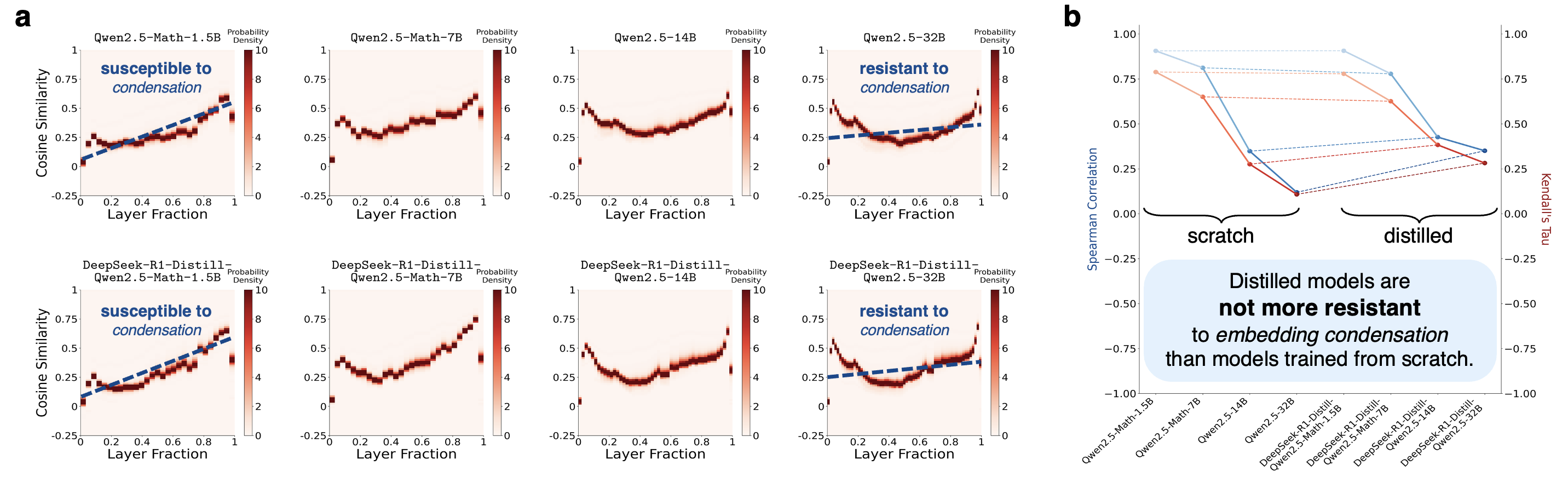
Not resolved by knowledge distillation from a larger model (Figure 5).
This paper presents an observation-driven improvement on language model training.
We observe a geometric phenomenon which we term embedding condensation, where token embeddings collapse into a narrow cone-like subspace in smaller language models. We then design a training objective called dispersion loss to counteract the effect.
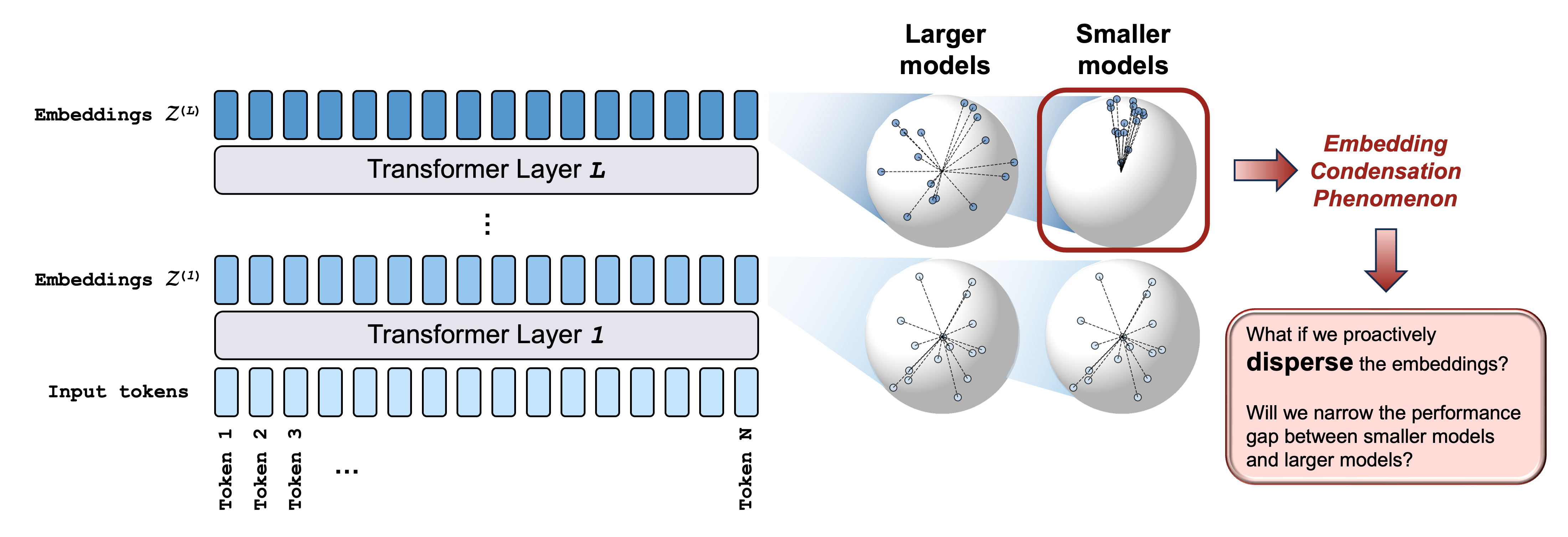
Feature 1: Larger model, less condensation.
Within the
same model family, smaller models exhibit more severe embedding condensation, with token
embeddings collapsing toward near-parallel directions, while larger models resist this
collapse.
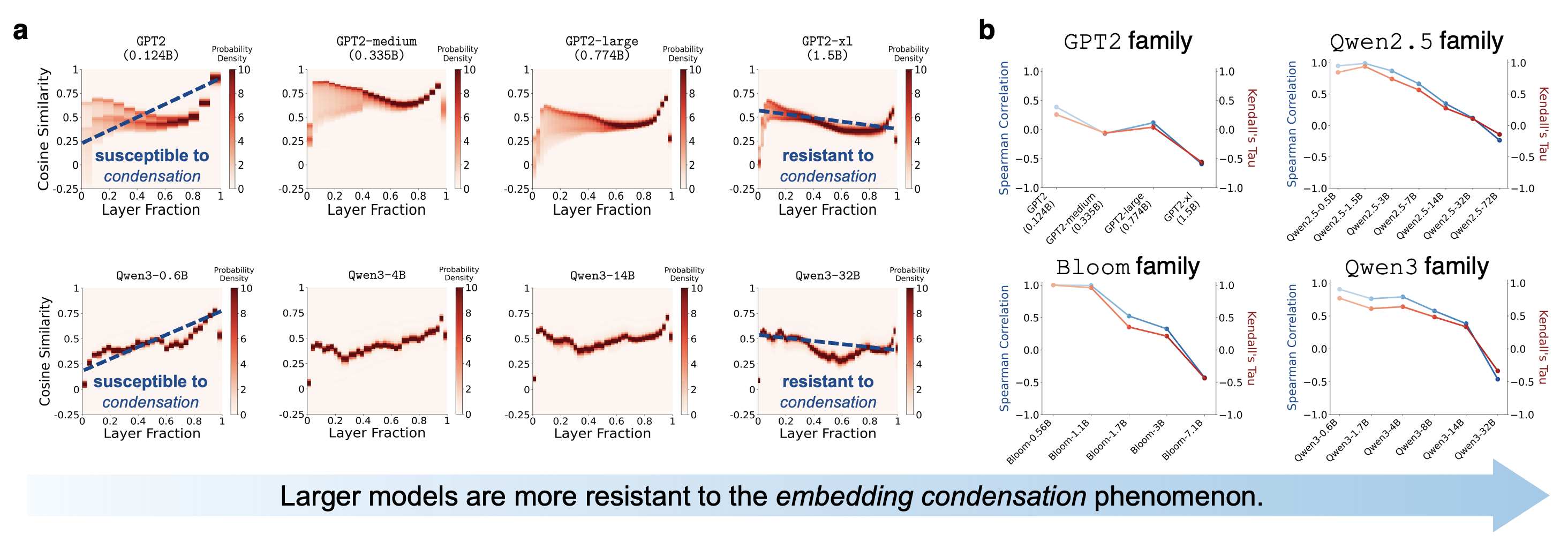
GPT2, Qwen3-0.6B) are
susceptible to condensation, since token cosine similarities become increasingly
positive as the embeddings proceed to deeper layers. In contrast, larger models (e.g.,
GPT2-xl, Qwen3-32B) are more resistant to embedding
condensation. b. Quantifications using Spearman correlation and Kendall’s
Tau demonstrate a consistent trend of “larger model, less condensation”
across multiple families of language models. Additional results can be found in Figure
S1.
This effect is also quite robust to the choice of input datasets.
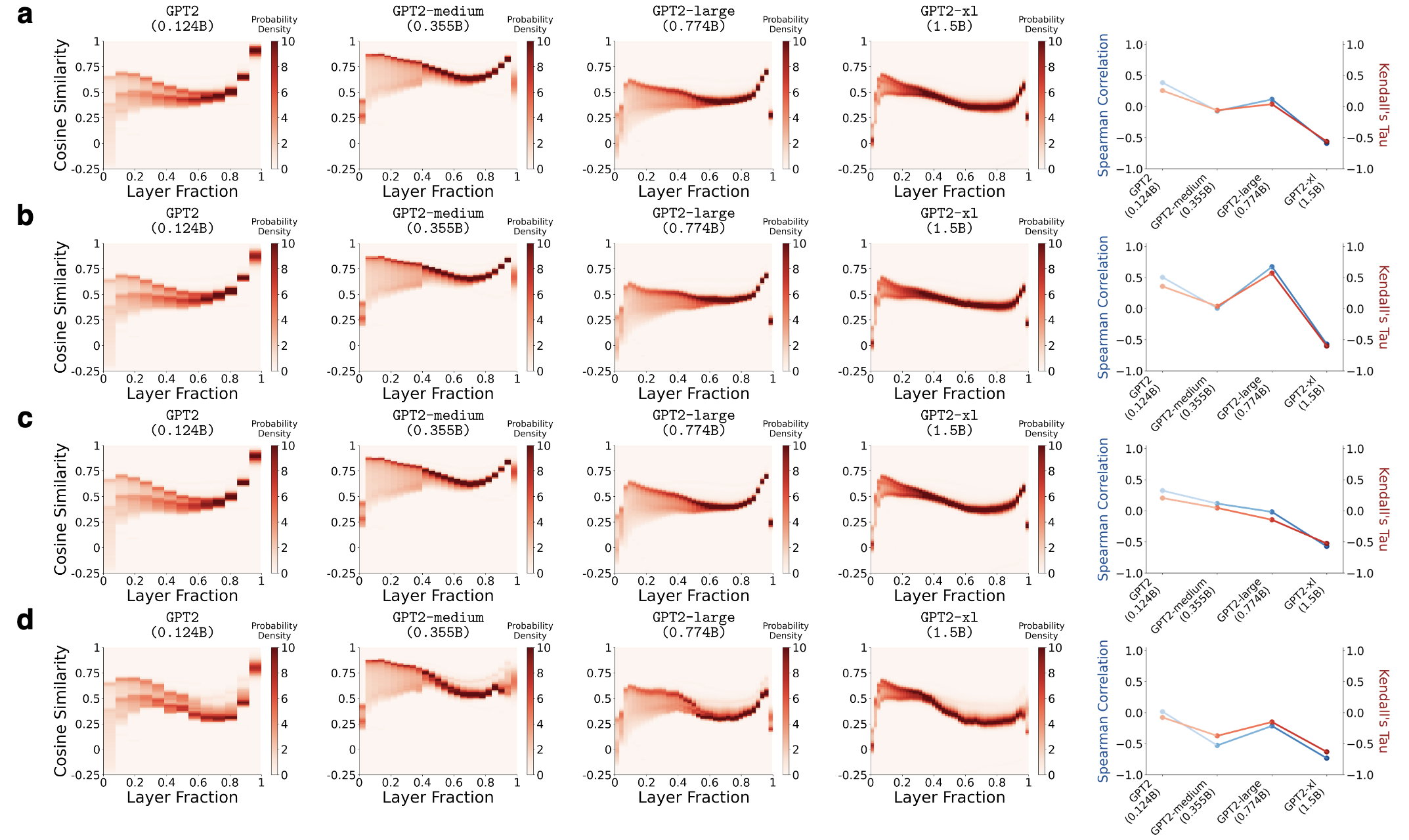
wikitext, (b) pubmed_qa, (c)
imdb, and (d) squad.
Feature 2: Reproducible when controlling for
confounders.
To isolate the effect of model size from other confounding
factors, we conduct a controlled experiment where we pre-train GPT2-like models, varying
only the MLP dimension while keeping all other components fixed, including the number of
layers, embedding dimension, dataset, and training settings. The same phenomenon is
observed.

GPT2-like models of varying sizes that differ only in MLP
dimension, while keeping all other factors fixed, including the number of layers,
embedding dimension, dataset, and training configuration. The resulting models exhibit
consistent trends in embedding condensation, shown qualitatively (panel a) and
quantitatively (panel b). Horizontal dashed lines are added to panel a for
easier visual comparison.Feature 3: Condensation occurs early on.
The embedding
condensation phenomenon emerges at model initialization and is gradually mitigated, not
exacerbated, by pre-training.
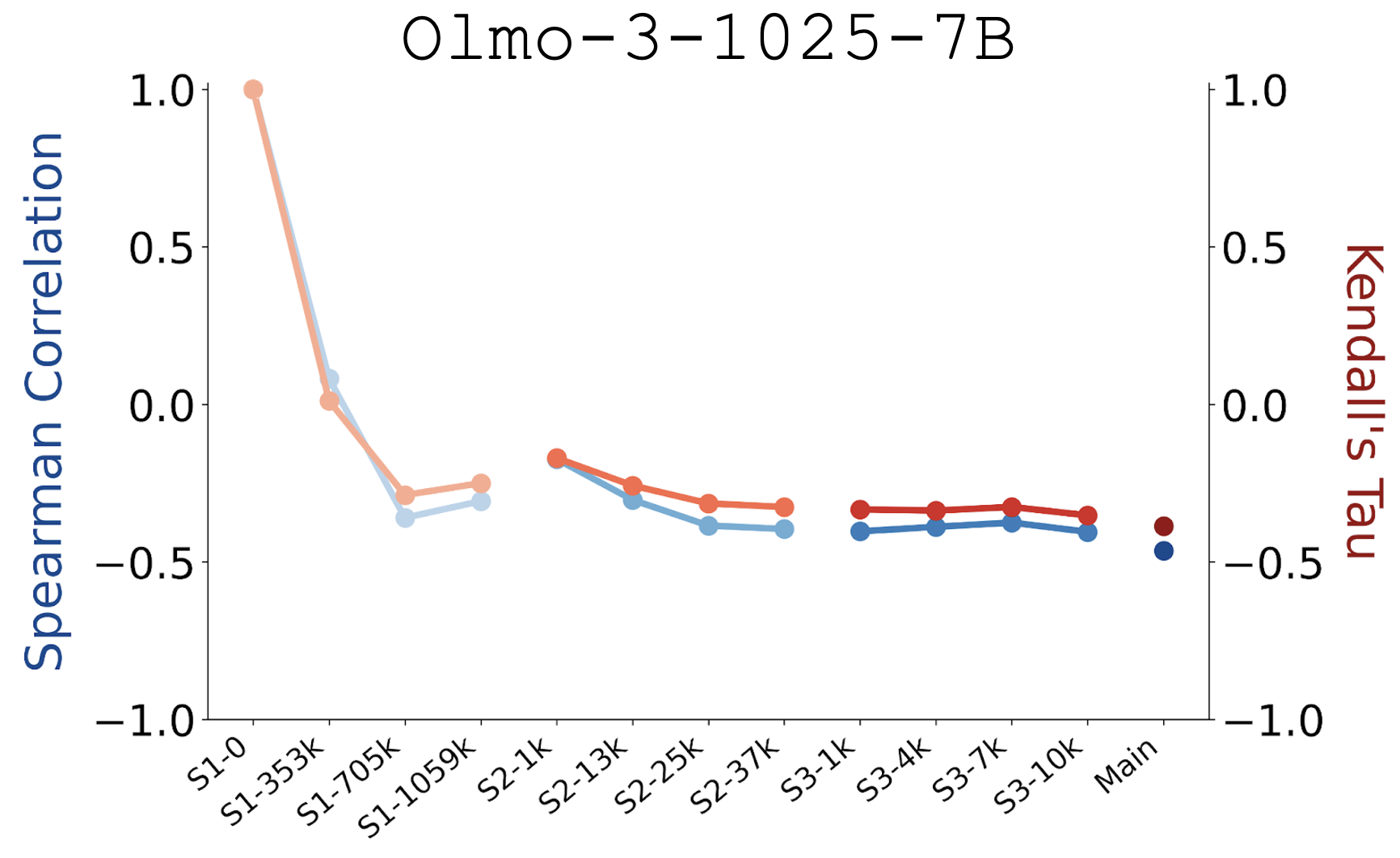
Olmo-3-1025-7B spanning initialization, intermediate pre-training stages,
and the final base model. Each checkpoint is annotated by its training stage and the
number of training tokens.
Feature 4: Distillation is not a solution.
Knowledge
distillation from a larger model does not transfer the desired resistance to embedding
condensation.
Dispersion loss
Embedding condensation reduces the
expressivity of Transformers by collapsing token embedding vectors into narrow cones,
under-utilizing the representation space. We hypothesize that by dispersing embeddings
during training, smaller models can achieve representational qualities more similar to
larger models, thus narrowing the performance gap without increasing the number of
parameters.
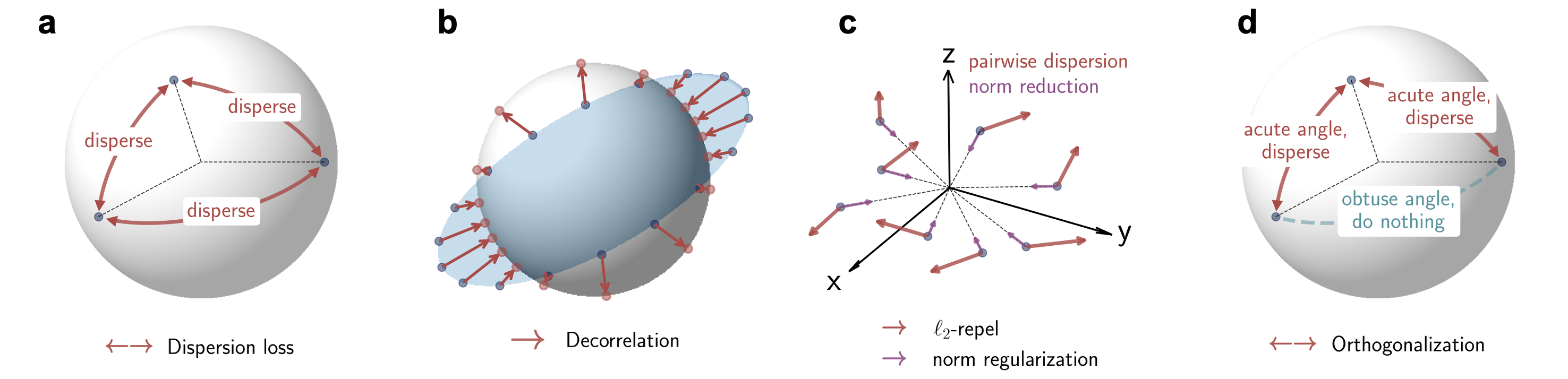
Our dispersion loss is inspired by the "Diffuse and Disperse" paper with practical modifications.
log-sum-exp trick for numerical stability, which differs from log(mean(exp(·))) only by an additive constant. For
ℓ2-repel, we include a norm regularization term to prevent unbounded
expansion of embeddings. For Orthogonalization, the distance margin is fixed to 1⁄2 since we use angular
distance, where 1⁄2
corresponds to orthogonality and thus serves as the ideal margin.

Dispersion loss counteracts the embedding condensation effect during mid-training and pre-training. A qualitative result is shown below, while more quantitative results can be found in the paper.
Conclusion
Larger language models are better than
smaller language models, but might not merely because they have more parameters. It
can be partially attributed to how they organize the information in the latent
representations. We hope to see future efforts along this interesting direction.
If you are thinking about reproducing this work or borrowing pieces of it, here are my two cents.
I personally highlight a few directions that seem potentially meaningful.
@inproceedings{liu2026dispersion,
title={Dispersion loss counteracts embedding condensation and improves generalization in small language models},
author={Liu, Chen and Sun, Xingzhi and Xiao, Xi and Van Tassel, Alexandre and Xu, Ke and Reimann, Kristof and Liao, Danqi and Gerstein, Mark and Wang, Tianyang and Wang, Xiao and Krishnaswamy, Smita},
booktitle={International Conference on Machine Learning},
year={2026},
organization={PMLR}
}